HELM
An AI research loop turned 20 GB of market tape into a governed, validated trading book.
The durable edge in a rank tournament is not a magic price signal. It is calibrated variance plus survival, discovered and validated by a research loop that runs hundreds of times.
We are ranked against 299 rivals each round, so the objective is return rank subject to survival.
| Scoring component | Weight | Implication |
|---|---|---|
| Return rank | 70% | Relative return drives the score |
| Drawdown rank | 15% | Shallow drawdowns are rewarded |
| Sharpe rank | 10% | Risk-adjusted quality counts |
| Risk discipline | 5% | Penalties for over-leverage |
Return rank dominates, but a single forced liquidation ends the campaign. The optimisation is return rank conditioned on never being eliminated.
Under realistic spreads and a one-bar delay, most price-prediction alpha proved fragile or absent.
- We tested signal families across FX majors, metals and crypto at five time frames.
- Most edges were thin or vanished entirely once costs and delay were applied honestly.
- That result was the most useful of the first week: it forced the real question, if the signal edge is thin, where does the win come from?
The durable edge is calibrated variance plus survival, which is exactly what the scoring rewards.
Hold a high-quality, low-drawdown book, then dial variance up or down against live rank and time to the next cut. Most of the field sits in one of the two losing zones.
A single repeatable loop, run hundreds of times, does the work.
The same disciplined loop applies to every idea, so results are comparable and the audit trail is complete. The loop, not any single signal, is what we are presenting.
We searched 98 candidate strategies across families, instruments and five time frames.
| Family group | Examples |
|---|---|
| Trend | CTA trend, momentum ignition |
| Mean reversion | z-score, band, spike reversal |
| Breakout & volatility | volatility breakout, channel |
| Flow & microstructure | flow momentum, order-book skew |
| Session & calendar | US-closed hours, London fix, macro event |
| Regularised ML | ridge, lasso, logistic, selection |
| Time frame | Candidates |
|---|---|
| 5 minute | 9 |
| 15 minute | 11 |
| 1 hour | 43 |
| 4 hour | 35 |
| Total | 98 |
Eight adversarial tests reduced 98 candidates to 22 genuinely diversified survivors.
- CPCV and PBO to test whether the edge is real or a lucky path.
- Regime and per-year checks: does it hold when conditions change?
- Stability and ablation: do neighbours agree, does each piece earn its place?
- Decay and cost: survive the entry lag and clear cost at its own frequency.
The resulting book compounds steadily, at a Sharpe above three and a drawdown under two percent.
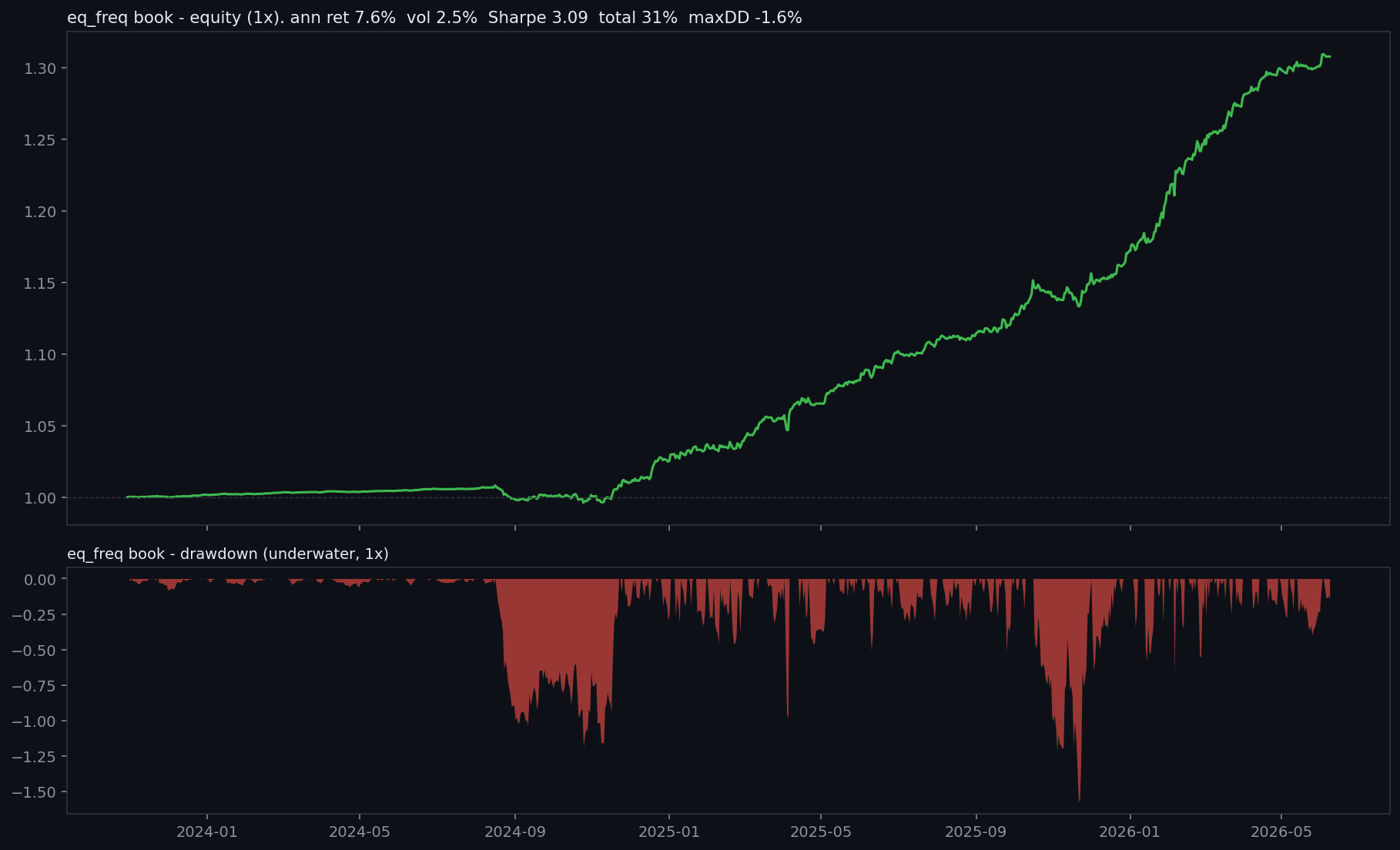
Even fully levered, a high-Sharpe book cannot win first place on return alone.
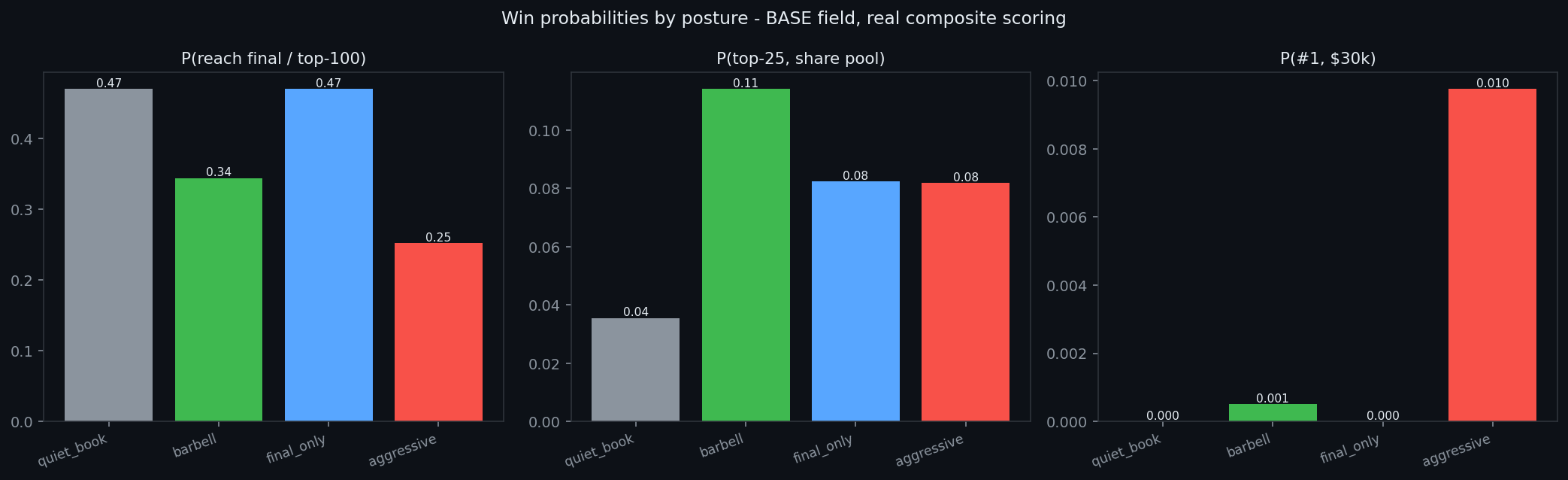
The quiet book reaches the final about 47% of the time, yet its probability of finishing first on return is effectively zero. Pushing to an aggressive posture only lifts P(first) to roughly 1%, while raising elimination risk. The return crown is a lottery; we decline to buy the ticket.
We therefore optimise for the prizes our edge can actually win.
| Prize | Basis | Our fit | Posture |
|---|---|---|---|
| First place, $30k | Return rank | Low | Decline the lottery; keep a live option only |
| Top-25 pool, $100k | Whole-event consistency | Medium | Survive every cut, place steadily |
| Best Sharpe | Whole-event Sharpe | High | A Sharpe above three is our natural edge |
| Best Technology, $10k | Judged | High | An AI-run research programme, on the record |
Survival-first execution protects the consistency and Sharpe prizes through every round; the technology entry is a separate, high-probability target judged on the work itself.
Leverage is calibrated per round: ten times through the cuts, twenty-five reserved for the final.
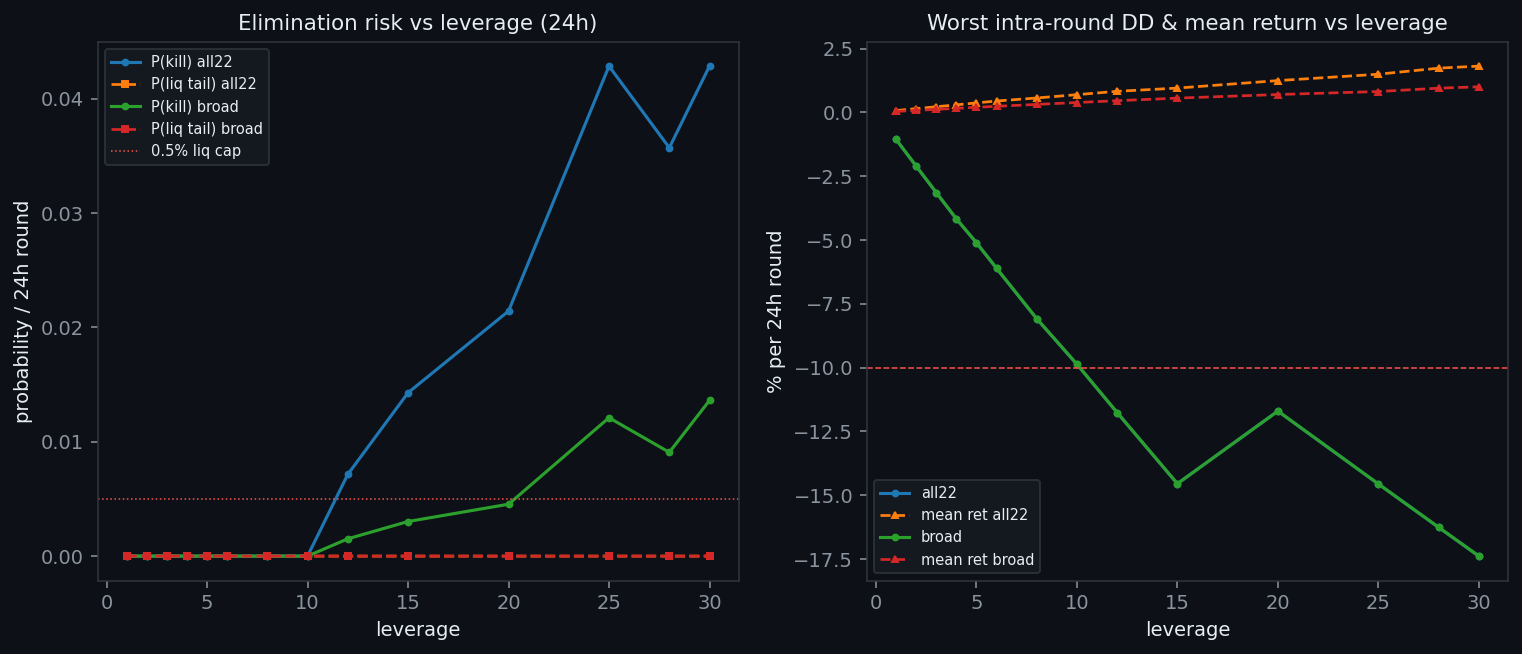
| Round | Leverage | Rationale |
|---|---|---|
| R1 to R3 | 10x | Survival ceiling; elimination risk near zero |
| Final, days 4 to 5 | 25x | Push for rank once survival no longer binds |
At 10x the book's forced-liquidation probability is effectively zero. The binding limit is our own 10% kill latch, which sits outside the model and can only de-risk.
The entire research programme was run by Claude, orchestrating specialised agents in parallel.
Claude proposed, tested, refuted and iterated. It caught its own data bias, conceded errors when challenged, and re-derived the answer. Many agents ran this loop at once, which is what made the search this thorough in the time available.
Four technologies, each with a defined job.
Ground truth was rebuilt from 20.8 GB of five-level order-book tape.
- 20.8 GB of five-level L2 tick data for FX and metals became bars, microstructure features and an executable cost model.
- A 730-day crypto history covered BTC, ETH, SOL and XRP, the assets the venue tape excludes.
- Cost was re-measured from the book itself. The only real cost is crossing the spread once per round trip, and it is small, so signal quality and survival are the true constraints rather than turnover.